
Generative timbre spaces
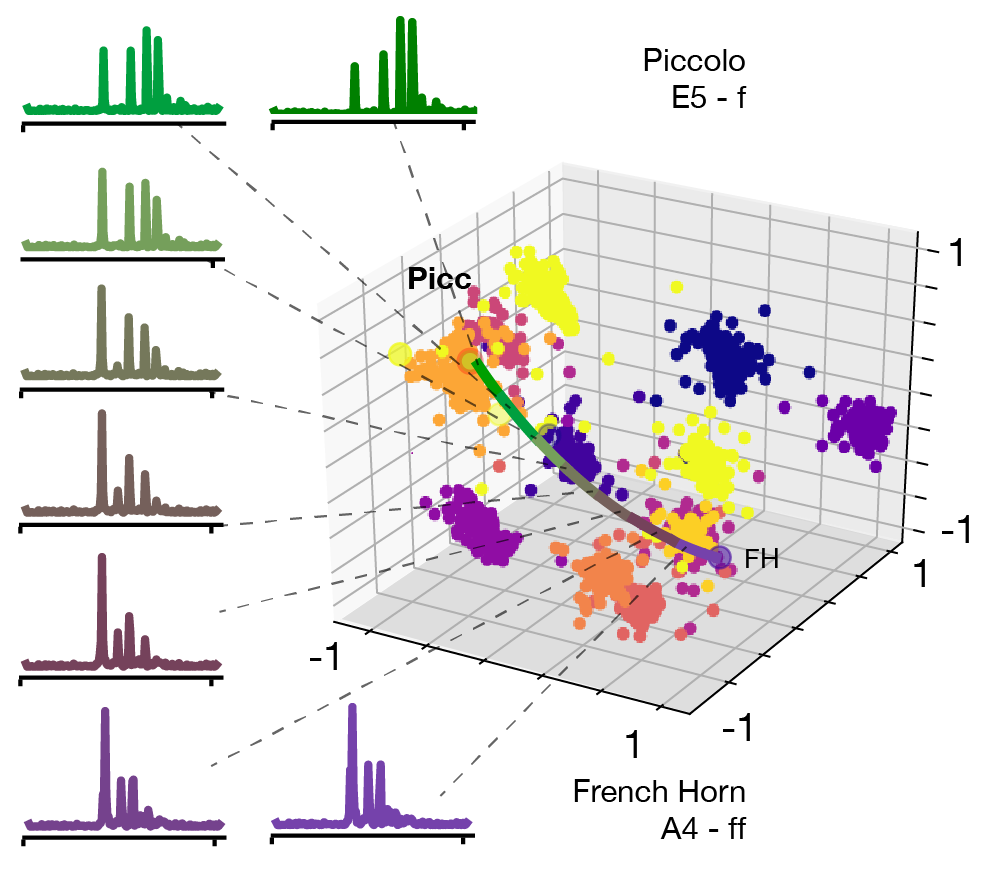
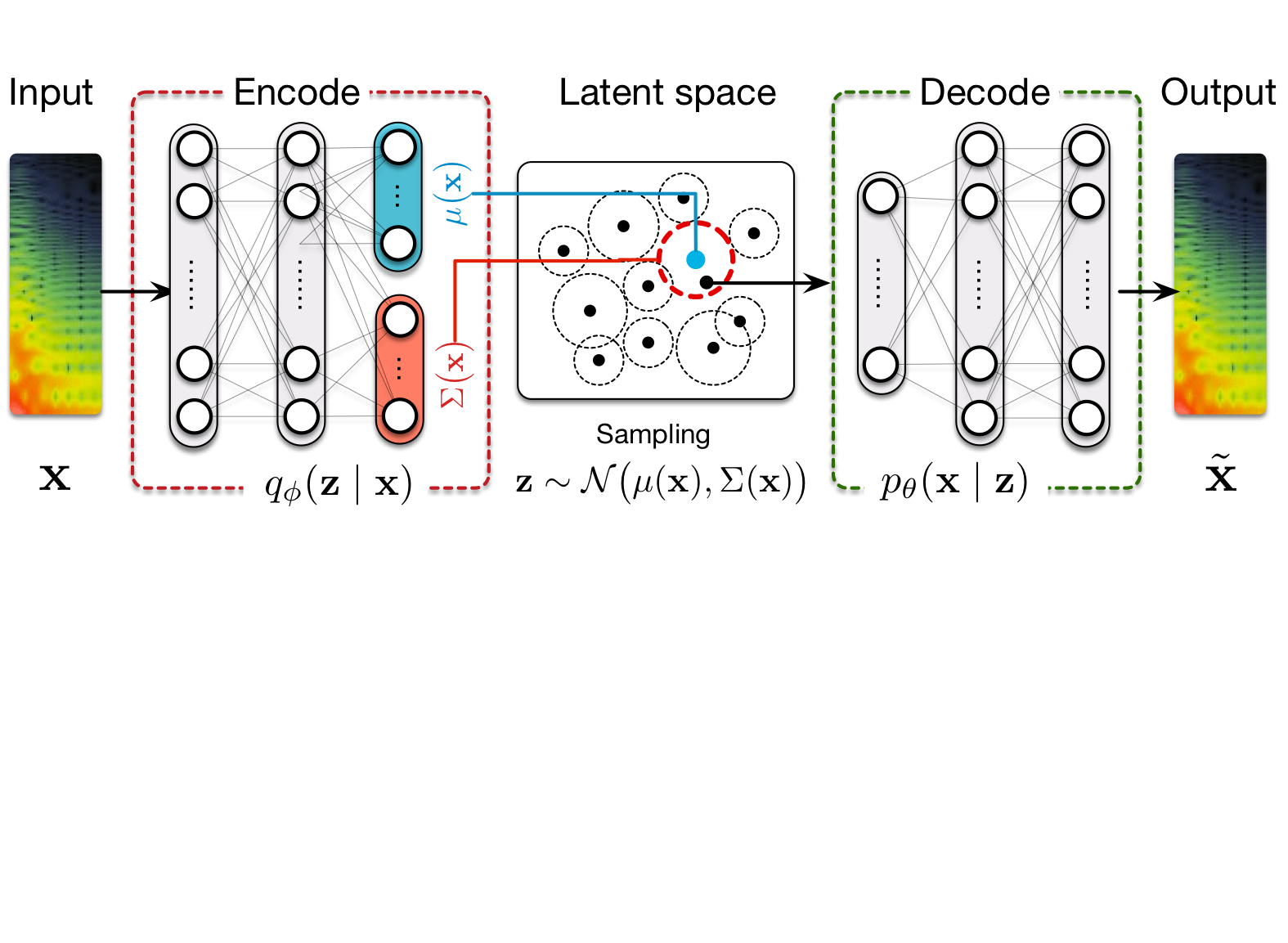
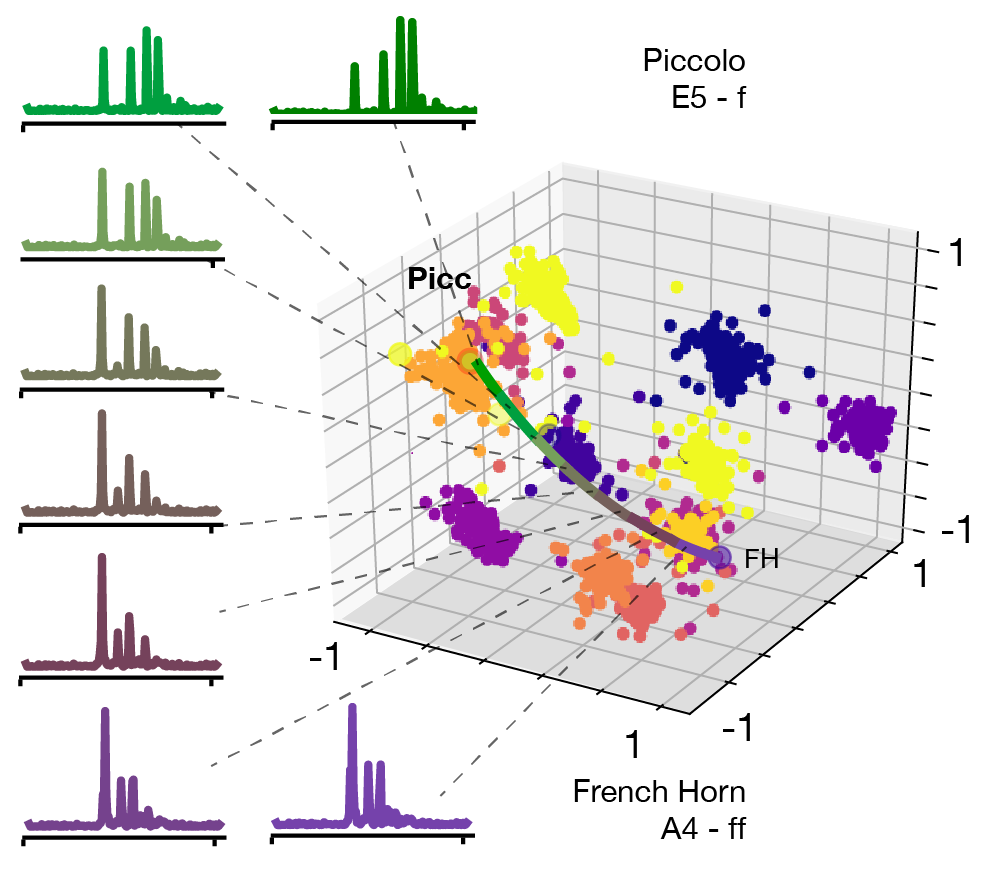
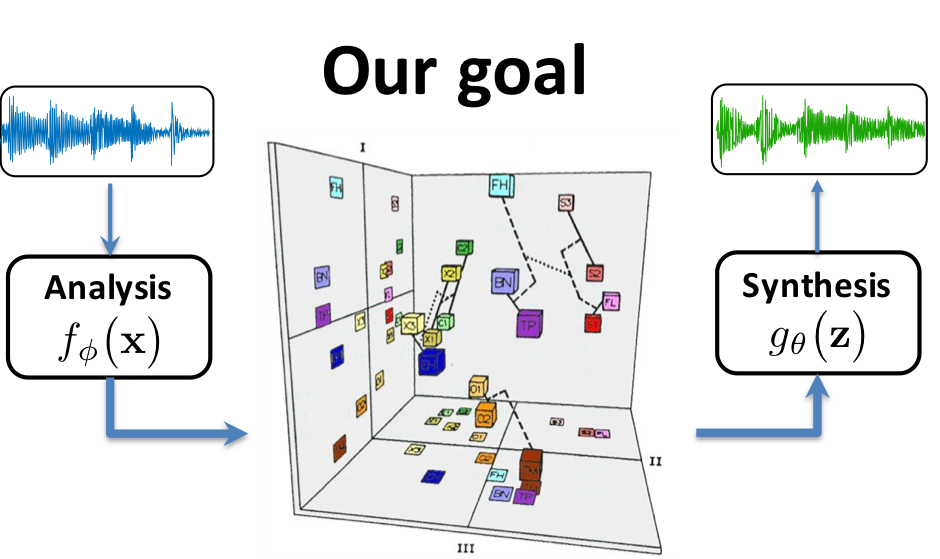
Timbre spaces have been used to study the relationships between different instrumental timbres, based on perceptual ratings. However, they provide limited interpretability, no generative capability and no generalization. Here, we show that variational auto-encoders (VAE) can alleviate these limitations, by regularizing their latent space during training in order to ensure that the latent space of audio follows the same topology as that of the perceptual timbre space. Hence, we bridge audio analysis, perception and synthesis into a single system.
Timbre spaces have been used in music perception to study the perceptual relationships between instruments based on dissimilarity ratings. However, these spaces do not generalize to novel examples and do not provide an invertible mapping, preventing audio synthesis. In parallel, generative models have aimed to provide methods for synthesizing novel timbres. However, these systems do not provide an understanding of their inner workings and are usually not related to any perceptually relevant information. Here, we show that Variational Auto-Encoders (VAE) can alleviate all of these limitations by constructing generative timbre spaces. To do so, we adapt VAEs to learn an audio latent space, while using perceptual ratings from timbre studies to regularize the organization of this space. The resulting space allows us to analyze novel instruments, while being able to synthesize audio from any point of this space. We introduce a specific regularization allowing to enforce any given similarity distances onto these spaces. We show that the resulting space provide almost similar distance relationships as timbre spaces. We evaluate several spectral transforms and show that the Non-Stationary Gabor Transform (NSGT) provides the highest correlation to timbre spaces and the best quality of synthesis. Furthermore, we show that these spaces can generalize to novel instruments and can generate any path between instruments to understand their timbre relationships. As these spaces are continuous, we study how audio descriptors behave along the latent dimensions. We show that even though descriptors have an overall non-linear topology, they follow a locally smooth evolution. Based on this, we introduce a method for descriptor-based synthesis and show that we can control the descriptors of an instrument while keeping its timbre structure.
Download the source code
View the paper on ArXiV