
Flow synthesizer
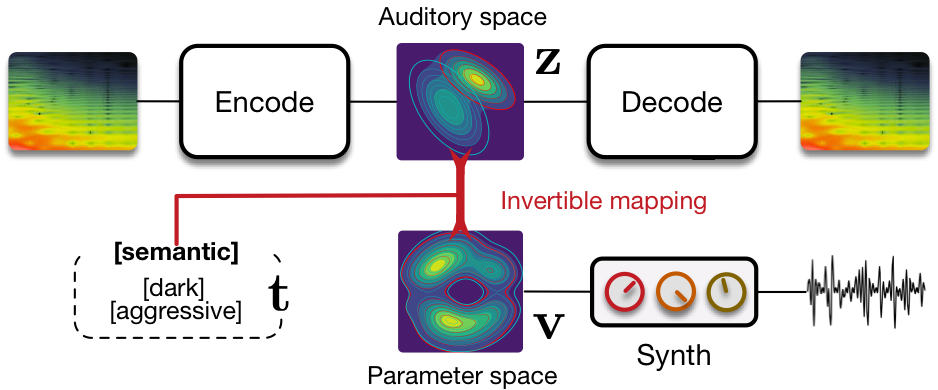
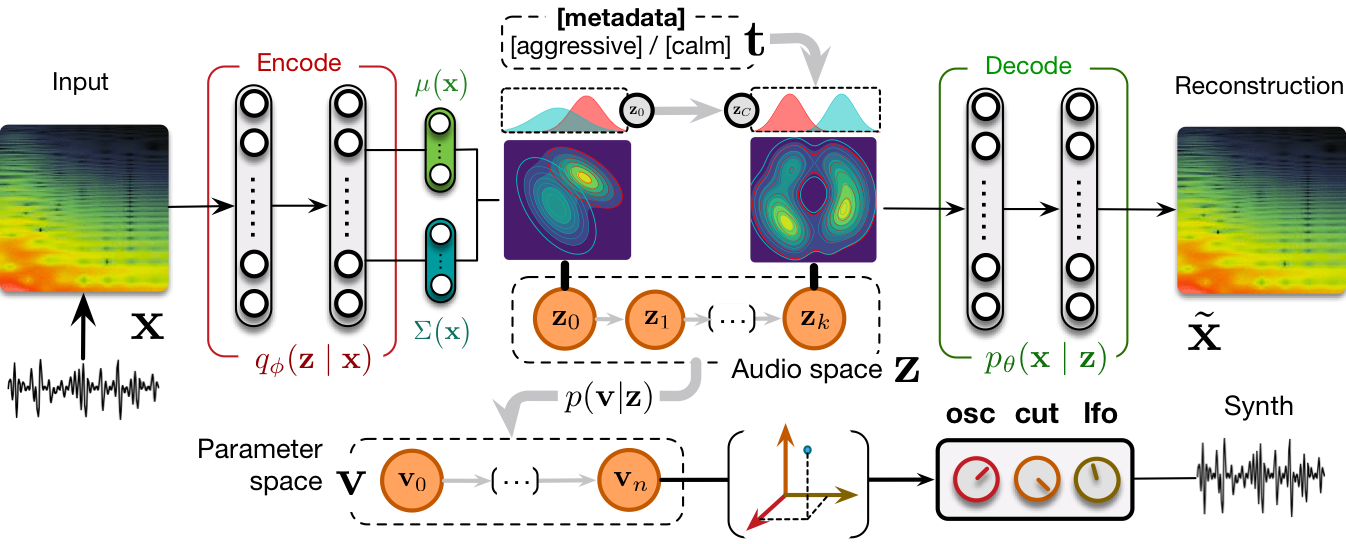
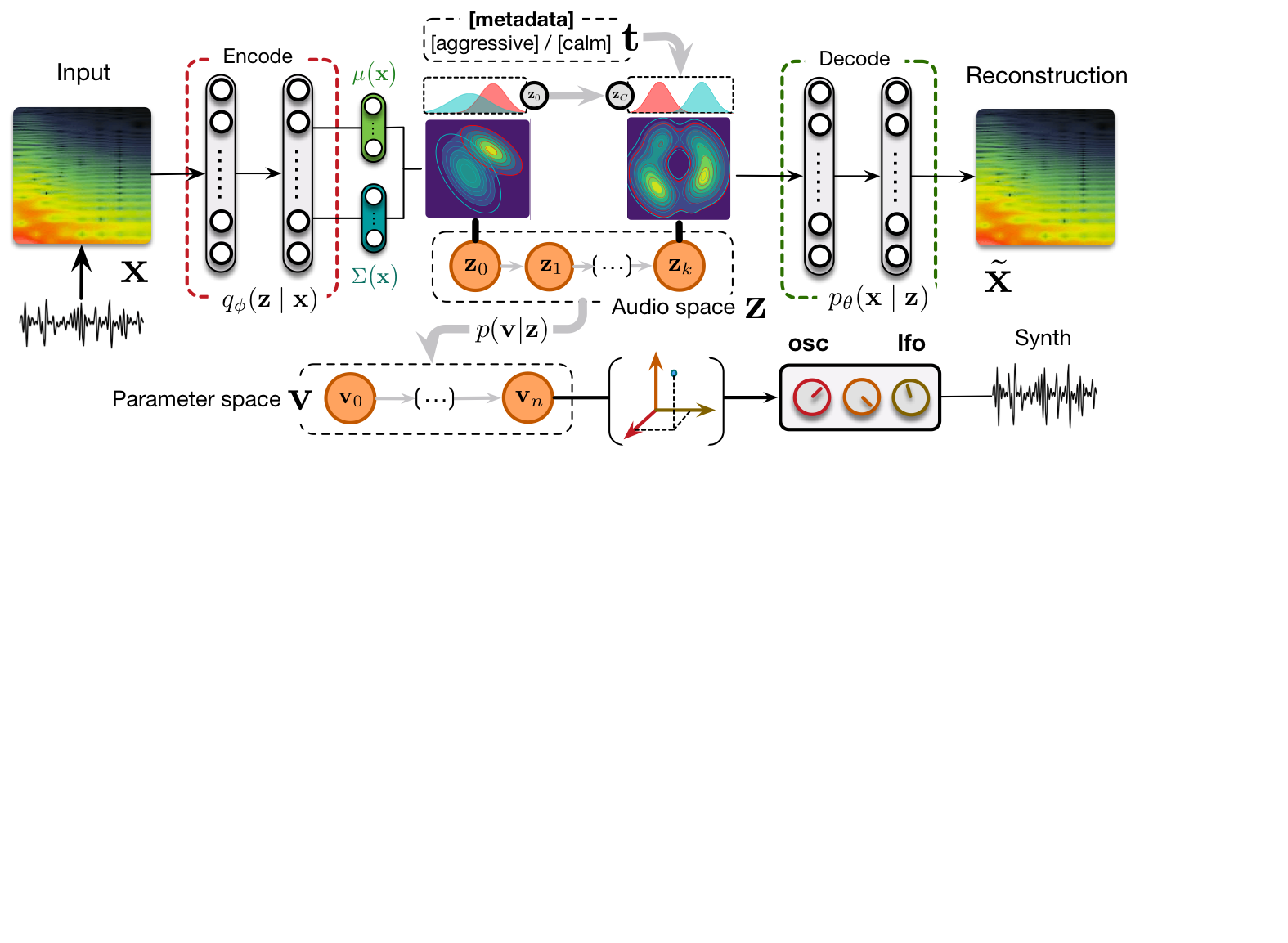
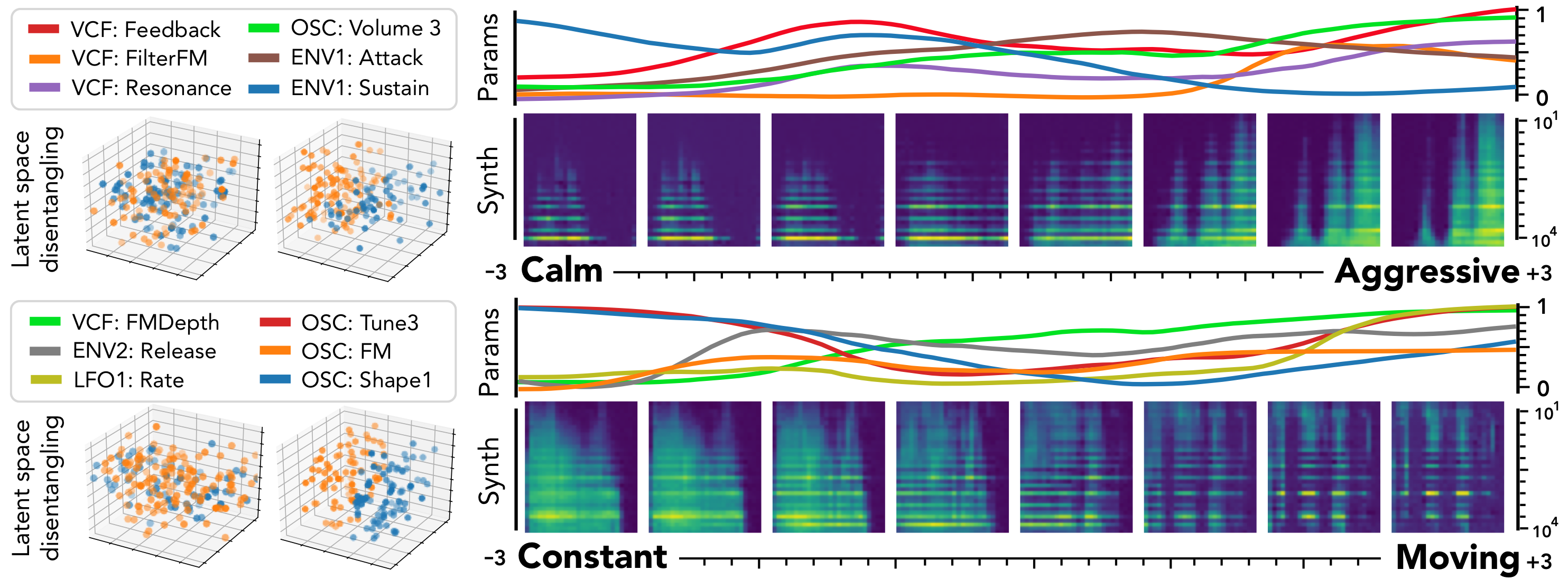
Sound synthesizers are pervasive in music and they now even entirely define new music genres. However, their complexity and sets of parameters renders them difficult to master. We created an innovative generative probabilistic model that learns an invertible mapping between a continuous auditory latent space of a synthesizer audio capabilities and the space of its parameters. We approach this task using variational auto-encoders and normalizing flows Using this new learning model, we can learn the principal macro-controls of a synthesizer, allowing to travel across its organized manifold of sounds, performing parameter inference from audio to control the synthesizer with our voice, and even address semantic dimension learning where we find how the controls fit to given semantic concepts, all within a single model.
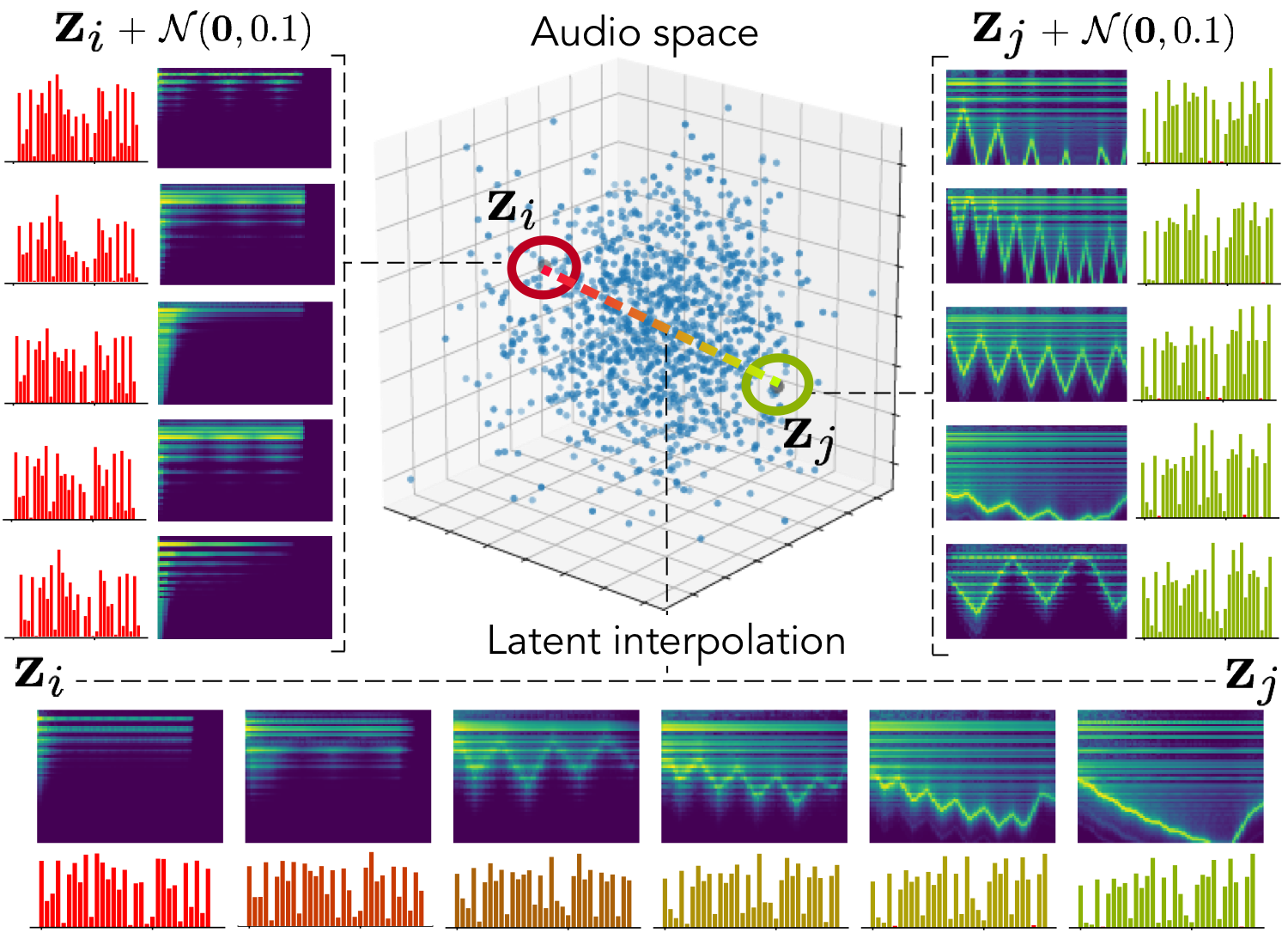
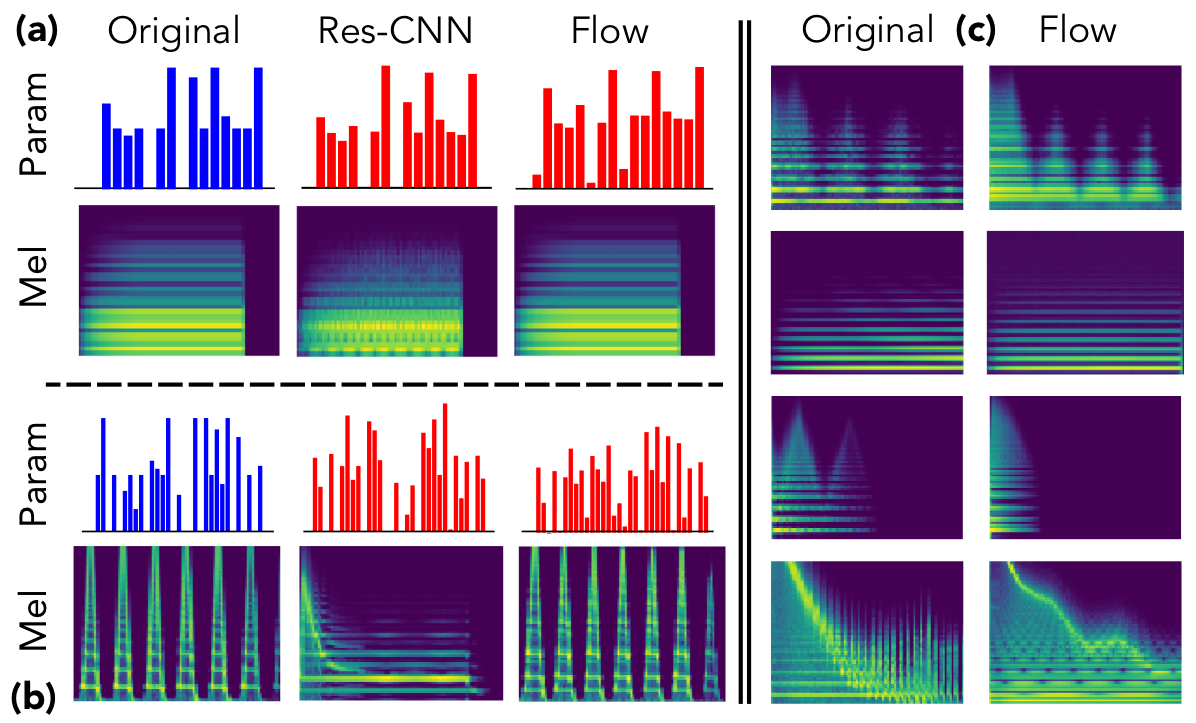
The ubiquity of sound synthesizers has reshaped music production and even entirely defined new music genres. However, the increasing complexity and number of parameters in modern synthesizers make them harder to master. Hence, the development of methods allowing to easily create and explore with synthesizers is a crucial need. Here, we introduce a novel formulation of audio synthesizer control. We formalize it as finding an organized latent audio space that represents the capabilities of a synthesizer, while constructing an invertible mapping to the space of its parameters. By using this formulation, we show that we can address simultaneously automatic parameter inference, macro-control learning and audio-based preset exploration within a single model. To solve this new formulation, we rely on Variational Auto-Encoders (VAE) and Normalizing Flows (NF) to organize and map the respective auditory and parameter spaces. We introduce the disentangling flows, which allow to perform the invertible mapping between separate latent spaces, while steering the organization of some latent dimensions to match target variation factors by splitting the objective as partial density evaluation. We evaluate our proposal against a large set of baseline models and show its superiority in both parameter inference and audio reconstruction. We also show that the model disentangles the major factors of audio variations as latent dimensions, that can be directly used as macro-parameters. We also show that our model is able to learn semantic controls of a synthesizer by smoothly mapping to its parameters. Finally, we discuss the use of our model in creative applications and its real-time implementation in Ableton Live.